
Why do we build Recommender Systems?
Recommender Systems are central to nearly every web platform that offers things - movies, clothes, any kind of commodity - to users. Recommenders analyze patterns of user behavior to suggest items they might like but would not necessarily discover on their own, items similar to what they or users similar to them have liked in the past. Personalized recommendation systems are reported to increase sales, boost user satisfaction, and improve engagment on a broad range of platforms, including, for example, Amazon, Netflix, and Spotify. Building one yourself may seem daunting. Where do you start? What are the necessary components?
Below, we'll show you how to build a very simple recommender system. The rationale for our RecSys comes from our general recipe for providing recommendations, which is based on user-type (activity level):
| interaction level | -> | recommendation approach |
| no interactions (cold start) | -> | most popular items |
| some interactions | -> | content-based items |
| more interactions | -> | collaborative filtering (interaction-based) items |
Our RecSys also lets you adopt use-case-specific strategies depending on whether a content- or interaction-based approach makes more sense. Our example system, which suggests news articles to users, therefore consists of two parts:
Let's get started.
We build our recommenders using a news dataset, downloadable here. Down below, once we move on to the collaborative filtering model, we'll link you to our user-article interaction data.
But first, let's set up and refine our dataset.
Using our dataset's columns, e.g., category, headline, short_description, date, we can extract only instances published after 2018-01-01.
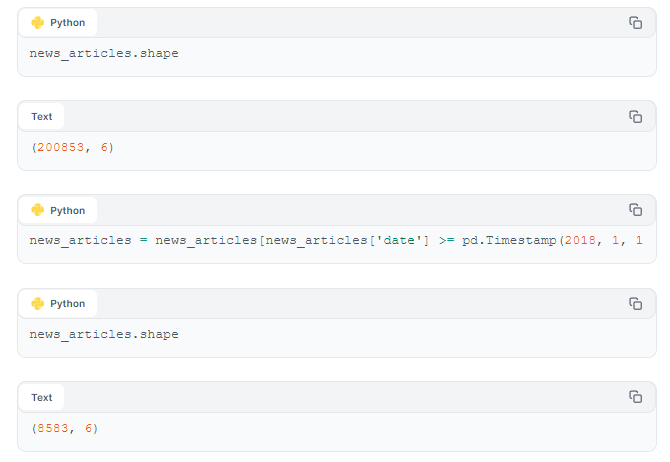
By filtering out articles published on or before 2018-01-01, we've refined our article set down from around 200K to roughly 8.5K.
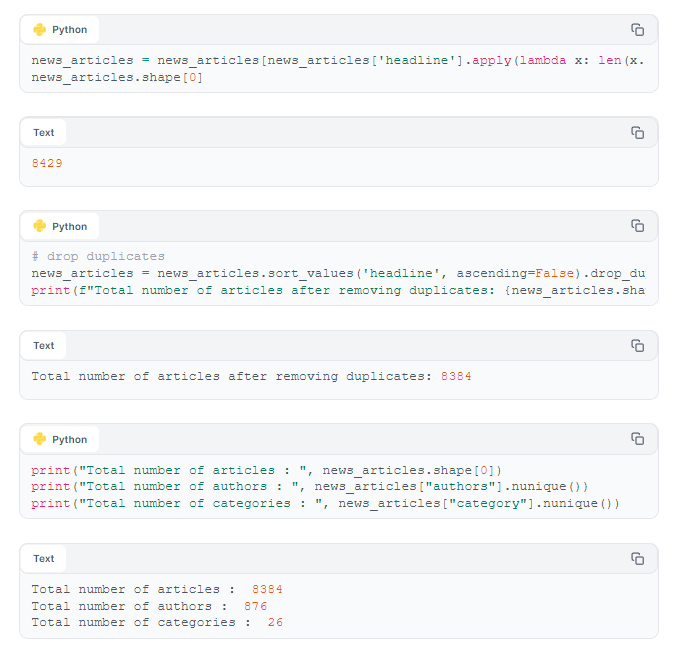
Next, we remove news articles with short headlines (shorter than 7 words), and then drop duplicates based on headline.
Next, we implement the first of our models: the content-based recommender. This recommender creates the same recommended list for all readers of a given article, displayed under the title "Similar Articles."
To identify which news articles are similar to a given (or "context") article, we obtain embeddings of the text associated with all articles in our refined dataset. Once we have the embeddings, we employ cosine similarity to retrieve the most similar articles. We use a model from the Sentence Transformers family that is often used for text-embedding tasks.
We add one more column to the dataset, populated with values concatenating the headline and the news article description. We do this so we can embed the text corpus of this column - i.e., calculate a vector representation of the articles.

We make index serve as article id, as follows:

For computational efficiency, we collect the first 500 articles. Feel free to experiment with a different subset or the full dataset, whatever fits your use case.
Below, we choose a context article, and then search for articles similar to it. Our aim is to see whether the short article descriptions are enough to evaluate whether the recommended articles are indeed similar to the context article.
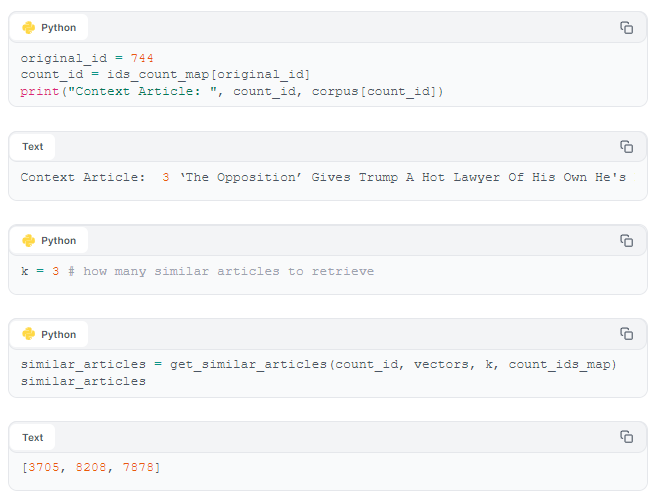
Next, we map the article ids to count ids. This lets us index articles in the corpus by their count ids.
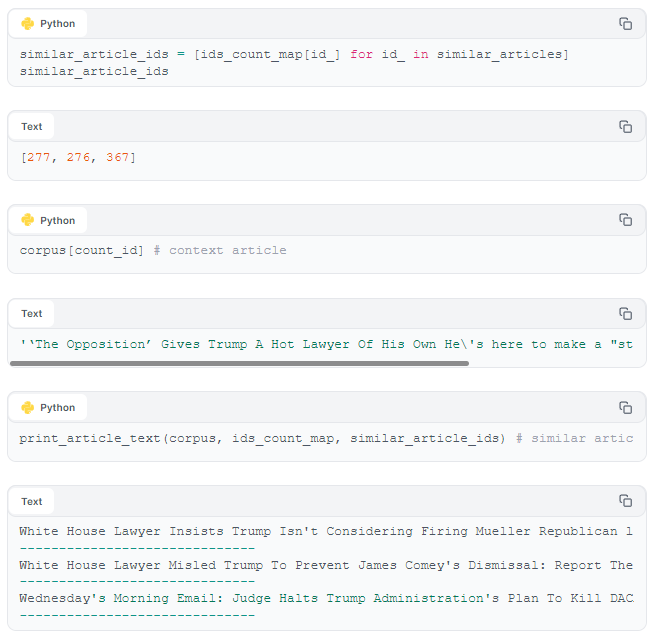
Our context article (above) was about Donald Trump. Our recommended articles also mention Mr. Trump. On a first glance evaluation of our content-based recommender looks good - it makes intuitive sense that people who read the context article would also be interested in reading our recommended articles.
Our system should of course be able to handle scenarios where a user has read more than one article. We therefore test our content-based recommender model to see if it can identify two different context articles, and find articles similar/relevant to both. We do this using simple vector averaging before doing our cosine similarity search. We use articles from the Entertainment and Business sections.
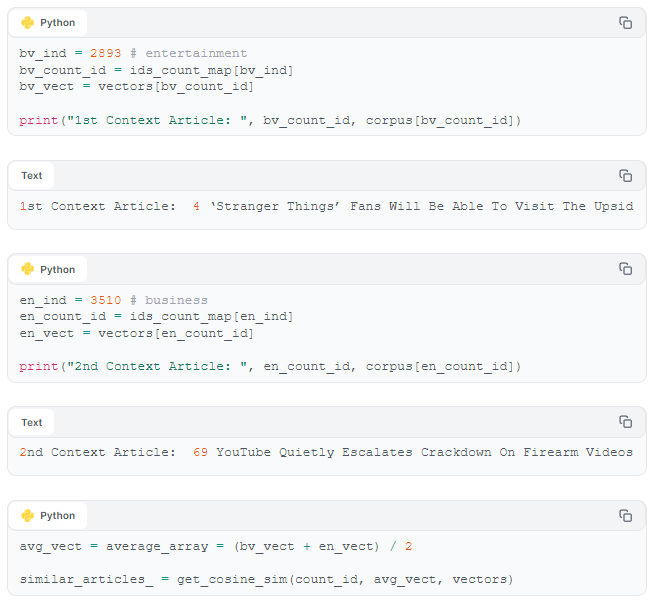
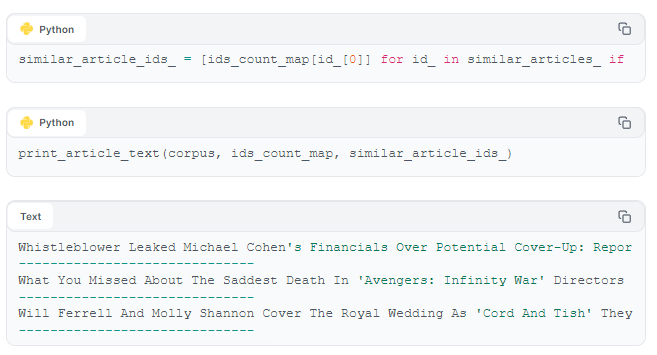
Our content-based model successfully provides articles relevant to both of the context articles.
The gold standard for evaluating recommender models is to A/B test - launch the models, assign a fair amount of traffic to each, then see which one has a higher click-through-rate. But a relatively easy way to get a first-glimpse evaluation of a recommender model (whether content-based or user-interaction-based) is to 'manually' inspect the results, the way we've already done above. In our use case - a news platform, for example, we could get someone from the editorial team to check if our recommended articles are similar enough to our context article.
Manual evaluation provides a sense of the relevance and interpretability of the recommendations. But manual evaluation remains relatively subjective and not scalable. To get a more objective (and scalable) evaluation, we can compliment our manual evaluation by obtaining metrics - precision, recall, and rank. We use manual evaluation for both our content-based and collaborative filtering (interaction-based) models, and run metrics on the latter. Let's take a closer look at these collaborative filtering models.
To be able to provide personalized article recommendations to our users, we need to use interaction-based models in our RecSys. Below, we provide implementations of two collaborative filtering approaches that can provide user-specific recommendations, in lists we title "Recommendations for you," "Others also read," or "Personalized Recommendations." Our implementations, called "Similar Vectors" and "Matrix Factorization," address the cold-start problem, and deploy some basic evaluation metrics - precision, recall, rank - that will tell us which model performs better.
To keep things simple, we'll first create a simulated user-article interaction dataset with the following assumptions:
Users are randomly assigned specific interests (e.g., "politics", "entertainment", "comedy", "travel", etc.). Articles are already categorized according to "interest", so we will simply 'match' users to their preferred interest category. We also assign a rating to the interaction: ratings ranging from 3 - 5 indicate a match between user interest and article category, ratings of 1 - 2 indicate no match. For our purposes, we'll filter out the low rating interactions.
For computational efficiency, we sample the first 3K articles, and limit the number of users to 300.
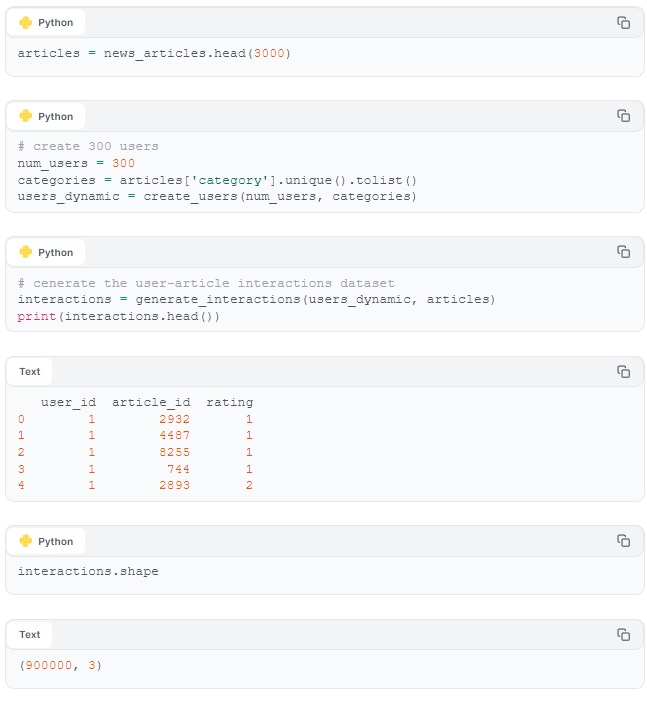
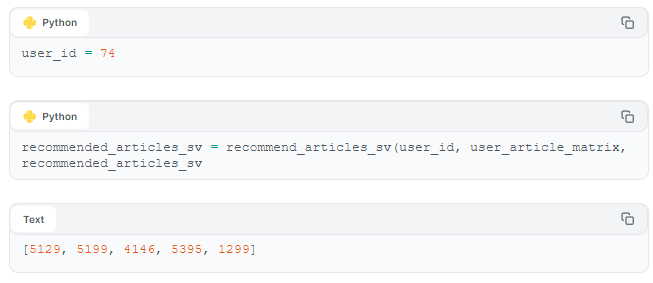
user_id 74, for example, has been assigned an interest in "travel". Let's see if we've successfully matched this user with "travel" articles.
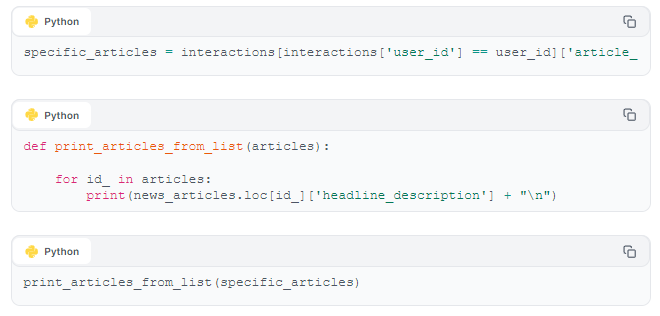
Text:
| United Airlines Mistakenly Flies Family's Dog To Japan Instead Of Kansas City The mix-up came just a day after a puppy died aboard a United flight. The 10 Best Hotels In The US In 2018, Revealed BRB, booking a trip to San Antonio immediately ✈️ Rogue Cat Rescued After Hiding Out In New York Airport For Over A Week Pepper is safe and sound! Yelp Users Are Dragging Trump Hotels By Leaving ‘S**thole’ Reviews “Perhaps the Trump brand could take some lessons from Norway, where they have the BEST hotels." You Can Fly Around The World For Less Than $1,200 See four cities across four continents in 16 days ✈️ Take A Virtual Disney Vacation With Stunning New Google Street View Maps Visit Disneyland and Disney World on the same day without leaving home. These Gorgeous Secret Lagoons Exist For Only Three Months A Year Lençóis might give off Saharan vibes, but the park is not technically a desert. The 5 Best (And Most Affordable) Places To Travel In April If you’re smart about where you place that pin on the map, you can even trade some rainy days for sunshine. The World's Best Food Cities, According To TripAdvisor Will travel for food 🍜 The Most Popular U.S. Destinations Of 2018, According To TripAdvisor Get inspired for your next getaway. These Rainbow Mountains In Peru Look Like They’re Straight Out Of A Dr. Seuss Book Sometimes we can’t help but wonder if Mother Nature specifically designed some places just for Instagram. The Most Popular Destinations In The World, According To TripAdvisor And where to stay in these spots when you visit. Why People Like To Stay In Places Where Celebrities Have Died Inside the world of dark tourism. The 5 Best (And Most Affordable) Places To Travel in March 1. Miami, Florida United Airlines Temporarily Suspends Cargo Travel For Pets The decision follows multiple pet-related mishaps, including the death of a puppy. The One Thing You’re Forgetting In Your Carry-On While you can’t bring that liter of SmartWater through TSA, you absolutely can bring the empty bottle to refill at a water fountain once you’re past security. What The Southwest Flight Can Teach Us About Oxygen Masks A former flight attendant called out passengers for wearing their masks incorrectly. Your Emotional Support Spider And Goat Are Now Banned On American Airlines The airline released a list of prohibited animals after seeing a 40 percent rise in onboard companions. Space Mountain With The Lights On Is A Freaky Experience See Disney's most famous coaster in a whole new light. Wild Brawls Turn Carnival Ship Into 'Cruise From Hell' Twenty-three passengers were removed for "disruptive and violent acts.” What Flight Attendants Really Wish You'd Do On Your Next Flight Take. off. your. headphones. United Bans Many Popular Dog And Cat Breeds From Cargo Holds After Pet Deaths The airline unveiled new restrictions in its pet transportation policy. Why There Are Tiny Holes At The Bottom Of Windows On Planes If you’ve ever been on a plane, chances are, you’ve probably looked out your window, only to notice a tiny hole at the bottom These Are The Most Expensive Travel Days Of The Year We all love a good travel deal, so avoid these two days. There are two days of the year that are the absolute most expensive Roller Coaster Riders Suspended 100 Feet In The Air, Facing Down, After Malfunction An "abnormality" halted the coaster at the worst possible time. |
Success! We see that user_id 74 has been matched with articles appropriate to their interest in "travel". Our user-interaction dataset appears to be effective in matching users with articles they would be interested in.
Now that we've successfully created our user-interaction dataset, let's get into the details of our two collaborative filtering models. To train them, we need to create training and test data.
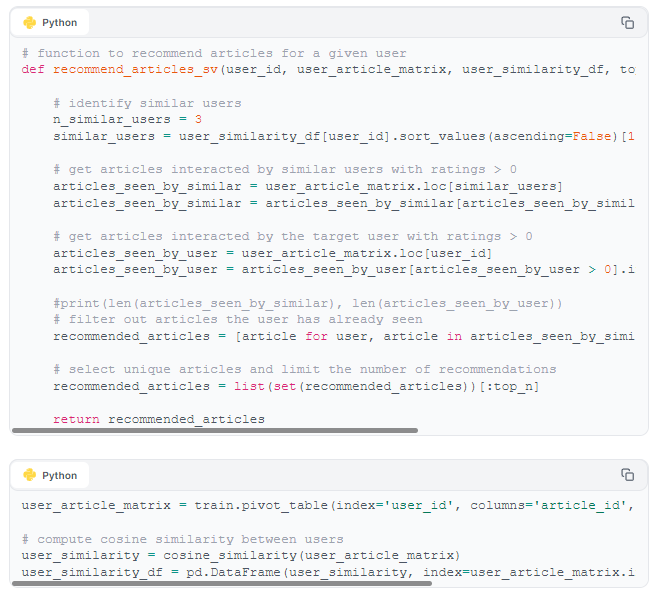
In our first collaborative filtering model, which we'll call "Similar Vectors," we use training data to create a vector for each user, populated by ratings they've given to news articles. Once we've created our user vectors, we can retrieve the most similar users via, for example, cosine similarity. And once similar users are identified, we can easily collect articles they've viewed that the context user hasn't yet seen.
Our second collaborative filtering model is a Matrix Factorization model, presented in this paper, with an efficient implementation in implicit package available here.
Recall the tiers of our general recipe for providing recommendations to particular user-types (based on their activity level). Our two collaborative filtering models can recommend items only to users that were part of training. And our content-based recommender can only recommend articles to users who have at least one interaction with content. Because new users start "cold" - without any platform activity, we have to recommend articles to them using a different strategy. One common solution to the cold start problem is to present these users with a list of the most popular items among all users.
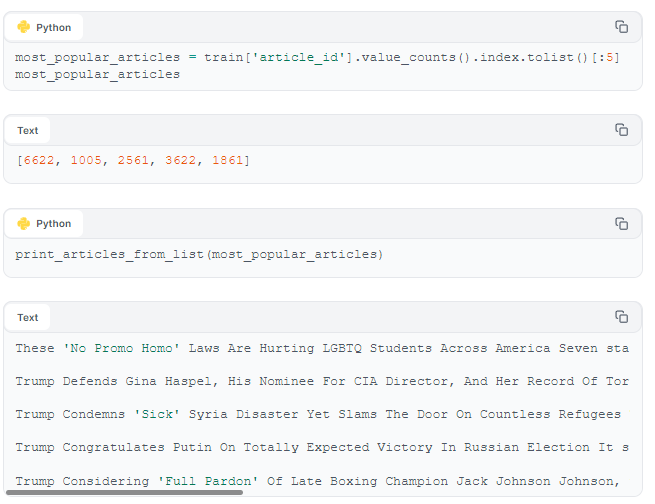
By suggesting Similar Articles, we hope to start moving cold start users to higher levels of platform activity, and expose them to our content-based and interaction-based recommendation approaches.
Before proceeding to training and testing of our collaborative filtering models, we need to split our interactions dataset into a training set and a test set.

With our interactions dataset split, we can set up our Similar Vectors model.
Next, let's set up our Matrix Factorization model.
A general MF model takes a list of triplets (user, item, rating), and then tries to create vector representations for both users and items, such that the inner product of user-vector and item-vector is as close to the rating as possible.
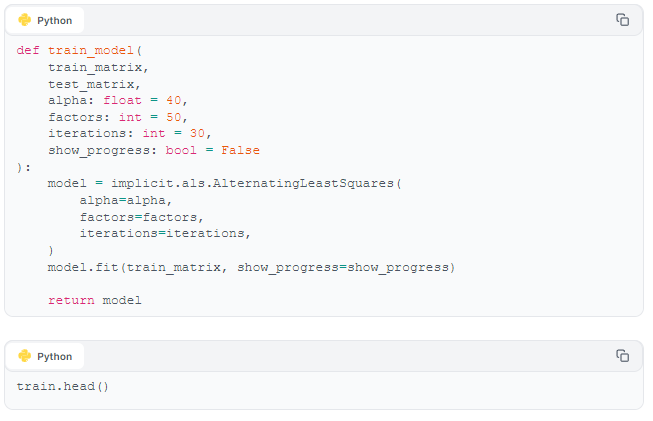
The specific MF model we use actually incorporates a weight component in the calculation of the inner product, and restricts the ratings to a constant value of 1, as shown in the following snippet.

MF model parameters
The MF model has several parameters:
We pass these hyperparameters as follows.
Now that we have both our Similar Vectors and Matrix Factorization models set up, let's start evaluating them, first 'manually', and then using metrics - precision, recall, and rank.
'Manual' evaluation
Below, we list the articles that the context user has actually read, and 'manually' compare this list to the lists generated by our two models.
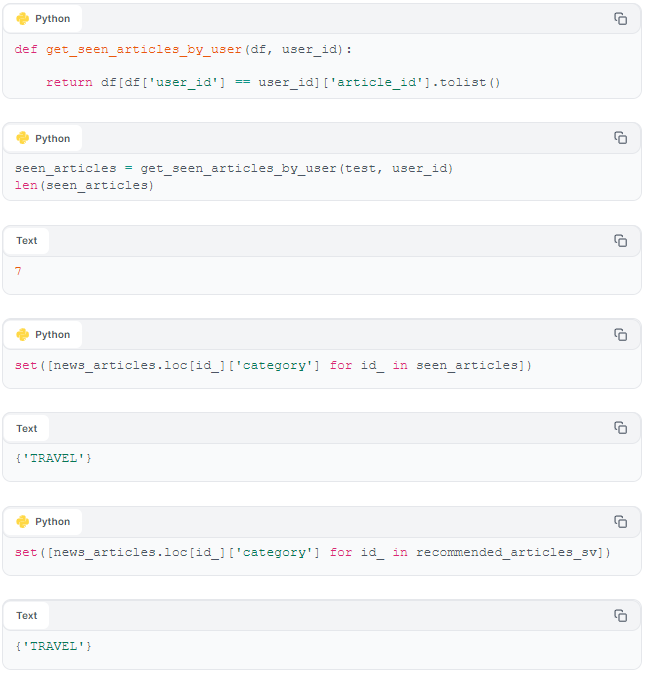
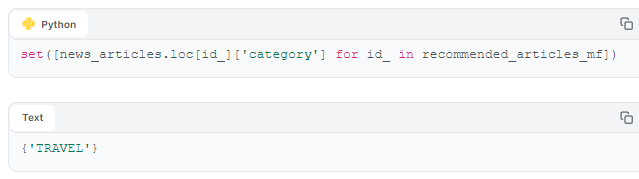
Evaluating manually, we can see (above) that both of our models recommend items that belong to the 'travel' category, which means that both models produce lists that are relevant. This is a good intuitive start to evaluating our two interaction-based models. But to provide a more objective (and scalable) evaluation of our models, we need some quantitative metrics.
Evaluation metrics
Measuring values such as precision and recall are good ways to complement our manual evaluation of our recSys's quality. Precision and recall evaluate recommendation relevancy in two different ways. Precision measures the proportion of recommended items that are relevant, while recall assesses the proportion of relevant items that are recommended. High precision means that most of the recommended items are relevant, and high recall means that most of the relevant items are recommended. Let's perform such an evaluation of our models, below.
We first extract a list of users who appear in both the training set and the test set, because - as we discussed in the "Cold Start" section - our models can generate recommendations for only those users whose interactions the models have been trained on.
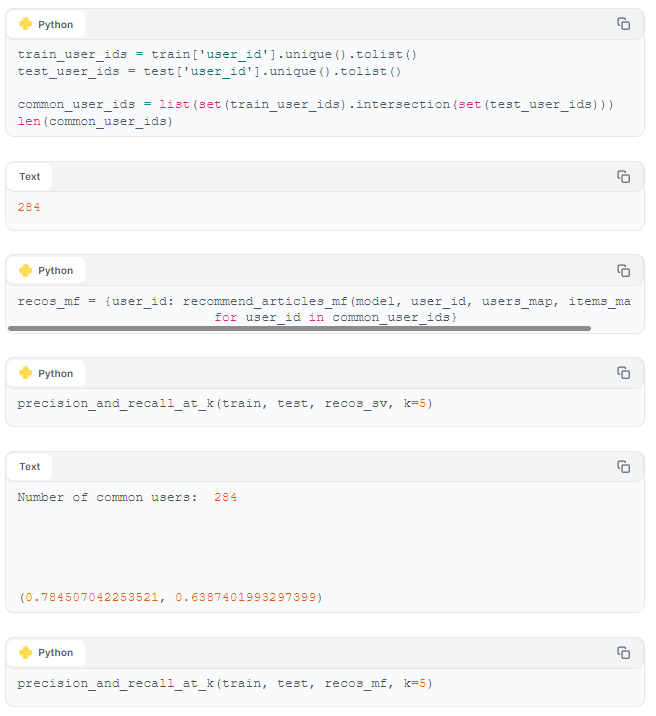
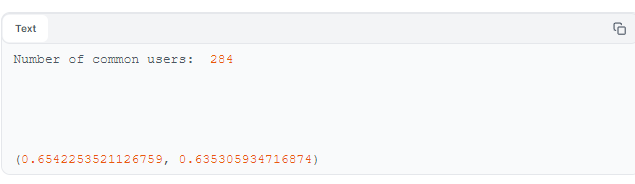
Position-based metrics
Recall and precision consider only the number of items common to both the recommendations and the test set. We can obtain a more complete picture by also generating metrics - for example, Mean Reciprocal Rank (MRR) - that measure the position (rank) of relevant items. MRR can provide an indication of whether our model does a good job of recommending the most relevant items to users first.
MRR is calculated as the average of the reciprocal ranks of the first correct answer for a set of queries or users. The reciprocal rank is the inverse of the rank at which the first relevant item appears; for example, if the first relevant item appears in the third position, the reciprocal rank is 1/3.
MRR is particularly useful when the position of the first relevant recommendation is more consequential than the presence of other relevant items in the list. It quantifies how effective a recSys is at providing the most relevant result as early as possible in a recommendation list. High MRR values indicate a system that often ranks the most relevant items higher, thereby increasing the probability of user satisfaction in scenarios where users are likely to consider only the top few recommendations or answers.
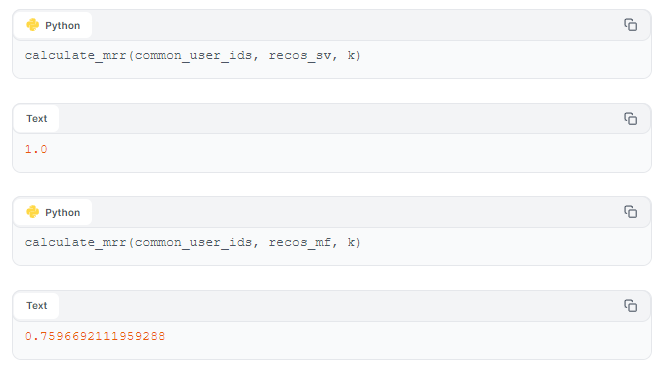
Both precision-recall and MRR results indicate that, for our simulated dataset at least, the Similar Vectors approach gives better recommendations than the Matrix Factorization model. However, it's important to note that our models may perform differently with real-world data.
In sum, we've implemented a RecSys that can handle the broad range of use cases encountered by any web platform that recommends things to users. Our RecSys incorporates three different approaches to handle recommendations for users of all three (zero, low, and higher) activity level types, as well as content-based ("Similar articles") and personalized (interaction-based) strategies ("e.g., "Recommendations for you," etc.) amenable to different sections of your web platform.
Read article here.
